WOW…. finally it come as Netbeans plugin after long awaited. I can now get rid of my own Darcula customisation.
Thank you all contributors who make this happen.



WOW…. finally it come as Netbeans plugin after long awaited. I can now get rid of my own Darcula customisation.
Thank you all contributors who make this happen.
Facing an issue where the email scheduler job keep sending duplicate activation email to user after they registered to the system.
After some troubleshooting time, found the culprit was actually spring schedule job running separately in separate node under cluster environment.
I then decide to “borrow” the idea from Liquibase on how it ensure only one instance running the changeset at one time. I first create a table call schedule_lock with column below:
CREATE TABLE scheduler_lock ( id integer NOT NULL, job_type character varying(50), is_lock boolean, lock_time timestamp without time zone, lock_by character varying(255), CONSTRAINT pk_scheduler_lock PRIMARY KEY (id) )
By having the job_type column, we can store different schedule job status in single table. lock_time and lock_by simply store the lock time and host name for easy debugging later. So the idea behind is pretty simple, any job will need to check against the lock status and their job type before running the job.
For eg: Node A run the job, it own the lock by updating is_lock to TRUE, lock_time and lock_by to current time and host name. Now Node B kicks in with the same job, it then check against the column, found is_lock = TRUE, it know some node already performing the job, so it can have some rest time by discard it’s own job.
After Node A complete it’s job, it will then release the lock by updating is_lock to FALSE, lock_time and lock_by to null.
And here is the code snippet for getting and releasing the lock.
public boolean getLock(SchedulerJobType jobType, String author) {
log.debug("[{}] getting the lock", author);
Session session = sessionFactory.getCurrentSession();
Criteria criteria = session.createCriteria(SchedulerLock.class);
criteria.add(eq("jobType", jobType.getCode()));
SchedulerLock scheduleLock = (SchedulerLock) criteria.uniqueResult();
if (scheduleLock.getIsLock().equals(Boolean.FALSE)) {
scheduleLock.setLock(Boolean.TRUE);
scheduleLock.setLockBy(author);
scheduleLock.setLockTime(new Date());
session.update(scheduleLock);
log.debug("[{}] got the lock", author);
return true;
}
return false;
}
public void releaseLock(SchedulerJobType jobType, String author) {
log.debug("[{}] releasing the lock", author);
Session session = sessionFactory.getCurrentSession();
Criteria criteria = session.createCriteria(SchedulerLock.class);
criteria.add(eq("jobType", jobType.getCode()));
criteria.add(eq("lockBy", author));
try {
SchedulerLock scheduleLock = (SchedulerLock) criteria.uniqueResult();
if (scheduleLock.getIsLock().equals(Boolean.TRUE)) {
scheduleLock.setLock(Boolean.FALSE);
scheduleLock.setLockBy(null);
scheduleLock.setLockTime(null);
session.update(scheduleLock);
log.debug("[{}] released the lock", author);
}
} catch (HibernateException e) {
log.debug("Not able to release lock by current thread {} due to {}", author, e.getCause());
}
}
OK, seems everything is now in place and my spring scheduler is “cluster safe”, Yay !
BUT … when the job run again with this new implementation, some weird behavior again happen.
Node A and Node B got the lock one after another, Node A release the lock successfully, but Node B throw an exception when releasing the lock. Logs below explain the situation:
#Node A 2016-02-02 03:12:00,000 DEBUG EmailServiceImpl: Email scheduler job started... 2016-02-02 03:12:00,013 DEBUG SchedulerLockDAOImpl: [Node-A] getting the lock 2016-02-02 03:12:00,022 DEBUG SchedulerLockDAOImpl: [Node-A] got the lock ..... 2016-02-02 03:12:06,199 DEBUG SchedulerLockDAOImpl: [Node-A] releasing the lock 2016-02-02 03:12:06,204 DEBUG SchedulerLockDAOImpl: [Node-A] released the lock 2016-02-02 03:12:06,210 DEBUG EmailServiceImpl: Email scheduler job end successfully...
#Node B 2016-02-02 03:12:00,000 DEBUG EmailServiceImpl: Email scheduler job started... 2016-02-02 03:12:00,013 DEBUG SchedulerLockDAOImpl: [Node-B] getting the lock 2016-02-02 03:12:00,019 DEBUG SchedulerLockDAOImpl: [Node-B] got the lock ..... 2016-02-02 03:12:05,082 DEBUG SchedulerLockDAOImpl: [Node-B] releasing the lock 2016-02-02 03:12:05,102 ERROR TaskUtils$LoggingErrorHandler: Unexpected error occurred in scheduled task.
Lets zoom into the code and see what is happening.
if (scheduleLock.getIsLock().equals(Boolean.FALSE)) {
scheduleLock.setLock(Boolean.TRUE); //<-- Node A
scheduleLock.setLockBy(author);
scheduleLock.setLockTime(new Date());
session.update(scheduleLock); //<-- Node B
log.debug("[{}] got the lock", author);
return true;
}
In this situation, the only possibility I can think of is Node B run the job first and got the lock by updating the record into database, but before Node B commit the changes into database, Node A kicks in safely with lock status still FALSE, so it then overwrite the lock status updated by Node B just almost immediately.
After some thought, I come out with an idea to make them run in different time by setting random Thread sleep time for each of the job and guess what, problem solved 🙂
@Scheduled(cron = "0 0 */2 * * ?")
public void sendActivationEmailTask() {
try {
int sleepPeriod = ThreadLocalRandom.current().nextInt(3, 60);
Thread.sleep(sleepPeriod * 1000);
String author = InetAddress.getLocalHost().getHostName();
if (schedulerLockDAO.getLock(SchedulerJobType.EMAIL, author)) {
// GET THE RECORD AND SEND EMAIL
schedulerLockDAO.releaseLock(SchedulerJobType.EMAIL, author);
}
} catch (Exception e) {
// LOG EXCEPTION
}
}
p/s: This might not be the best way, as the scheduler job will not run in exact 2 minutes we set, in this case will be 2 minutes + Thread sleep time from 1 – 60 sec. Leave me a comment if you have better idea.
Facebook will allow us to change our fan page username only once after we create, and we will need at least 25 likes to reset the username subsequently.
So what if you have already used up the first chance, and you don’t have 25 fans yet to change the new username?
Here is the tricks which you can by pass it:
1. Create new facebook account, then create a new fan page from the new account.
2. Goto https://www.facebook.com/username/ to create your new fan page username.
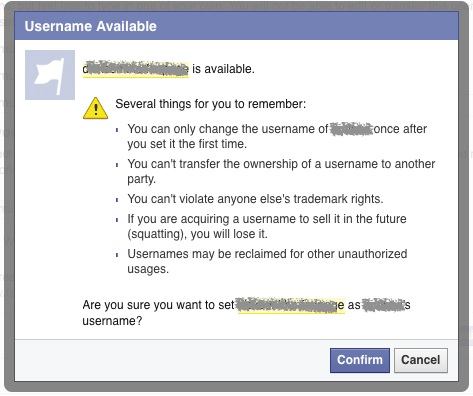
3. Goto Page Settings –> Page Roles then specify an email address (your real facebook login email) to be the page admin, then click Save to apply.

4. And you will see this.

5. You will receive an email as below after few second, just confirm and proceed to login if needed.

6. All set, you can now start managing the new fan page with new username. Follow step here to delete your temporary facebook account if you no longer using it, since this temporary account is also an admin for the fan page, so people who login using this account will be able to delete the fan page 🙂
If you are having custom servlet filter added into Spring security filter chain, and you are expecting custom filter exception throws should translate by ExceptionTranslationFilter but it doesn’t. Then you probably need to register your custom filter after ExceptionTranslationFilter as below.
protected void configure(HttpSecurity http) throws Exception {
http.addFilterAfter(new YOUR_CUSTOM_SERVLET_FILTER(), ExceptionTranslationFilter.class);
}
Recently I’m working on my personal project which expose RESTful API for client communication. In order to restrict some access to authenticated user only, It will then require client to login and issue a token upon login (also referring to Authentication token in this post), then client will use the token to identify them self for subsequent request.
Since I’m using Spring MVC framework for the implementation, @RequestHeader annotation come in handy. Just grab the header, set as parameter then call the business implementation for further processing. Sounds pretty easy ya 🙂
But when more and more method require this token, this become tedious where you keep adding @RequestHeader into your controller method just to get the token. So I decided to make use of filter for this.
After reading online documentation and article, I have created the scaffolding code @ github, which will do the following:
1. Get the “Authentication” header from each request.
2. Parse the header to get the token and query user based on the token.
3. Set the authenticated user object into SecurityContextHolder, and get back same user object anywhere within the request thread execution time. (By default the SecurityContextHolder uses a ThreadLocal to store details)
4. Each request will then check for role validity to access the business method.
Feel free to check out the code for study and fork it for your own usage, yet most important…………… have fun 🙂
Knowing SecurityContextHolder using ThreadLocal to store user related information. Meaning it does not use HttpSession due to some security concern (not discuss here). Wrote a main method to test that out.
public class NormalThreadExample {
public class MyThread implements Runnable {
private Integer normalInteger;
@Override
public void run() {
try {
Integer randomInt = (int) (Math.random() * 999);
System.out.println(Thread.currentThread().getName() + " SET " + randomInt);
normalInteger = randomInt;
Thread.sleep(2000);
System.out.println(Thread.currentThread().getName() + " GET " + normalInteger);
} catch (InterruptedException ex) {
// SOME HANDLER
}
}
}
public void haveFun() throws InterruptedException{
MyThread myThread = new MyThread();
Thread thread1 = new Thread(myThread);
Thread thread2 = new Thread(myThread);
thread1.start();
thread2.start();
}
public static void main(String[] args) throws InterruptedException {
NormalThreadExample example = new NormalThreadExample();
example.haveFun();
}
}
//Output : Thread-0 SET 737 Thread-1 SET 404 Thread-1 GET 404 Thread-0 GET 404
public class ThreadLocalExample {
public class MyThread implements Runnable {
private ThreadLocal<Integer> threadLocalInteger = new ThreadLocal<>();
@Override
public void run() {
try {
Integer randomInt = (int) (Math.random() * 999);
System.out.println(Thread.currentThread().getName() + " SET " + randomInt);
threadLocalInteger.set(randomInt);
Thread.sleep(2000);
System.out.println(Thread.currentThread().getName() + " GET " + threadLocalInteger.get());
} catch (InterruptedException ex) {
// SOME HANDLER
}
}
}
public void haveFun() throws InterruptedException{
MyThread myThread = new MyThread();
Thread thread1 = new Thread(myThread);
Thread thread2 = new Thread(myThread);
thread1.start();
thread2.start();
}
public static void main(String[] args) throws InterruptedException {
ThreadLocalExample example = new ThreadLocalExample();
example.haveFun();
}
}
//Output Thread-0 SET 3 Thread-1 SET 860 Thread-1 GET 860 Thread-0 GET 3
Note: Output result may be vary since it’s using random generator.
Almost a decade using NetBeans as my primary development IDE, I was always fell that NetBeans is lag behind IntelliJ especially their elegant Darcula theme which I like the most and some features offered is very responsive.
Anyway, I did not continue using it because the ultimate version is a bit pricy for me, and using the feature limited community edition make me feel like owning a jet aircraft but limited jet fuel.
So… download the latest NetBeans 8.1 and did some customization…
Da… Dang…. here is my new look and feel of NetBeans.
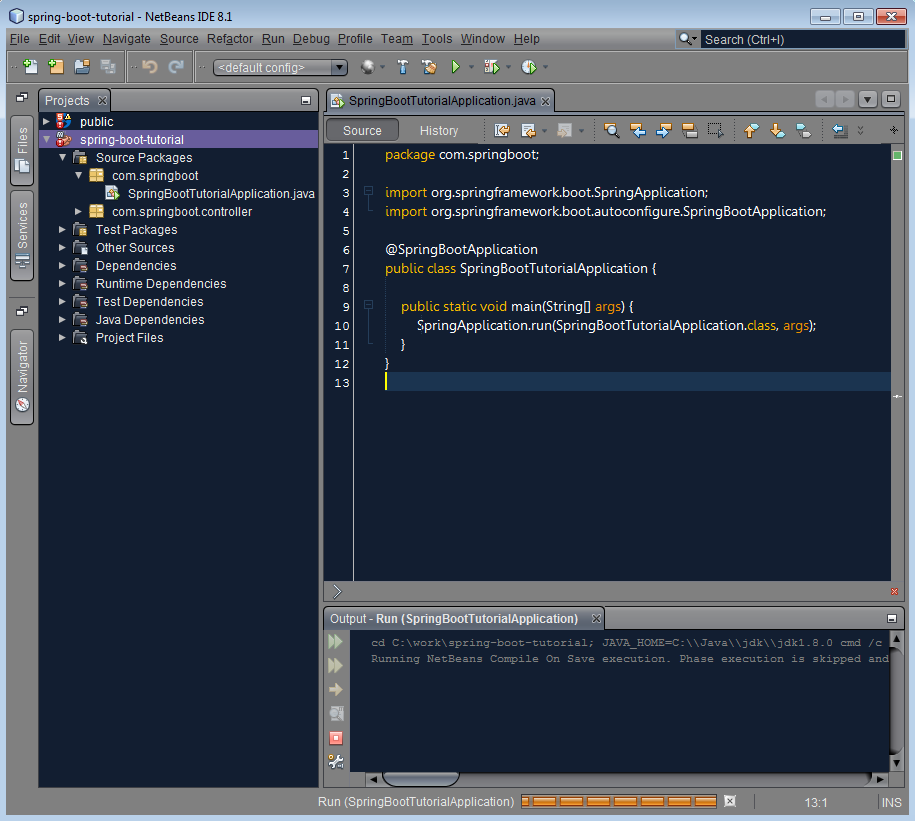
Anyway, the dark theme is not new, but I just realize using it with some other font and theme can be nice too 🙂
Besides that, the IDE now have better support for Html5/Javascript and AngularJS works much better than before (full release note here)
Here are my customization to share:

<entry javaType="java.lang.Float" name="line-height-correction" xml:space="preserve">
<value><![CDATA[1.1]]></value>
</entry>
Stumble upon 12factor.net when I was reading some technical documentation @ heroku.
Noted there are couple of suggestions worth practicing even we are not toward micro services paradigm.
By adapting their recommendation such as, Create a code base per app; Set only implicit dependency to the app for eg: runtime library, dependency manager which contrary to explicit dependency like curl, system tools; Store configuration in enviroment variable; Treat backing service (database, email server, authentication server) as independent resource….. etc… etc.. allow us not only create highly scalable application, but also increase agility of application development and deployment.
java.lang.RuntimeException: Cannot update previous revision for entity com.xxx.yyy.Users_audit and id 1 2015-11-12 16:22:19,168 ERROR [http-nio-8000-exec-3] EntitlementControllerAdvice: Unable to perform beforeTransactionCompletion callback org.hibernate.AssertionFailure: Unable to perform beforeTransactionCompletion callback ... ... ... Caused by: java.lang.RuntimeException: Cannot update previous revision for entity com.xxx.yyy.Users_audit and id 1 at org.hibernate.envers.strategy.ValidityAuditStrategy$1.doBeforeTransactionCompletion(ValidityAuditStrategy.java:223)
It’s because we configure ValidityAuditStrategy for audit strategy. Changing it to use DefaultAuditStrategy solve the problem, pheeeew…. (of course there are some trade off, which will not discuss here 🙂 )
From hibernate envers documentation:
ValidityAuditStrategy : Stores both the start revision and the end revision. Together these define when an audit row was valid.
DefaultAuditStrategy: Stores only the revision, at which an entity was modified.

Many years ago, what we do when we want to deploy and run our application after development? Typically we will setup physical machine, this normally including but not limited to system tools, jdk, python, database, application server etc..etc.. then deploy and run.
If we have multiple environment to deploy and run, then we repeat the same step for all environment, eg: dev, qa, staging, production.
After few years, people tend to make their life easier by not setup, deploy and run the application directly on physical machine, but using virtual machine where they can easily clone it for other environment (figure 1 show architecture of virtual machine).
 figure 1
figure 1
image from: www.docker.com
When more and more application run with different runtime environment, framework version, database vendor, server etc… Of cause deploying and running on top of virtual machine still works fine, but virtual machine is an operating system imitates dedicated hardware, meaning it shared host hardware system’s resources, which will then no longer available to the hosted applications.
Emerged of Docker container in perfect timing is good fit for this. It is a process that talks directly to the Linux kernel. And run as isolated process in host operating system. Meaning, we can now deploy our application in smaller container instead of virtual machine. (figure 2 show architecture of Docker).
 figure 2
figure 2
image from: www.docker.com
If you still confuse Docker is just another type of virtual machine, figure 3 might clear your doubts.
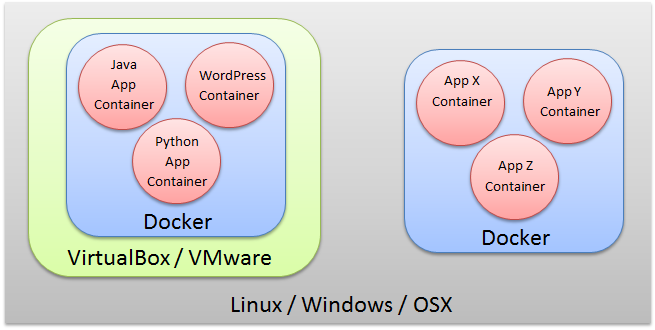
figure 3
p/s: Docker looks promising and it is really a good match for microservices, nevertheless, it has some security concern as they are sharing same kernel with host.
Container and virtual machine have different strength, hence should not viewed as competitors, but complimentary.
Source:
Docker documentation
Self-pace video tutorial
Virtualization vs. Containers: What You Need to Know
{kind=link}